
Stream Aggregate is the most efficient physical operator for value aggregation and generating distict rows. Stream here refers to record stream. Give you a typical example here. When you use SqlDataReader to retrieve reuslt from a query, the rows are read one by one by calling SqlDataReader.Read() method. You can say that you are streaming records from SQL Server to your client. If you perform aggregates in the stream, for instance, you are asked to count number of rows in the stream. In this example, you only need to increase the value with 1 to a variable in your application whenever Read() is involked with true returned. This is called Stream Aggregate.
queryplan
Query Plan (11) – Hash (1)
In my last post, I described Hash Joins which is showing as Hash Match physical operator in the graphical execution plan. Another place hash match is used is for aggregation. When columns in group by clause do have have indexes or SQL Server cannot determine whether the rows are sorted or not, SQL Server will perform a Hash match to get aggregates. If distinct keywork appears on the select list, but there is no indexes on the selected columns, a hash match will be used as well. This operation is called hash aggregate.
Query Plan (09) – Merge
Merge is a physical operator joining 2 sets together into one. Similar to Nested Loop, it can implement all logical join operations, such as outer join and inner join. Different from Nested Loop, Merge needs 2 input sets which are sorted on the joining keys. For instance, there are 2 piles of papers. The first pile includes customers’ basic information. Each paper has and only has one customers information. The first pile is sorted by customers’ ID. The second pile includes customers’ purchase information. Every customer might have 0 to many purchase orders. The second pile is sorted by customer’s ID. While merging taking place, operator takes one page from the first pile, Customer1 for instance, to compare the page from the second pile. If matched, return the combined information, then take the next page from the second pile and compare again. Until no more pages on the second pile can mach the current page from the first pile, which also means no more pages for Customer1 in the second pile, then the operator takes the second page from the first pile, and repeat this operation again and again until all the pages in the first pile get processed. This is a very effecient operation.
Query Plan (08) – Nested Loop Cont.
As we know that Nested Loop is a physical operator which can perform different kind of logical joins between 2 sets, SetA and SetB for instance. Does SetA joining SetB equal to SetB joining SetA from perfromance perspective(assume 2 sets have enough indexes)? It depends?
Statistics
The answer of the question I asked in my last post is Statistics. Query Optimizer is a cost(and rule) based optimizer. It calculates the costs for each operator based on its formulars behind and get the total estimated cost of query. If there are more alternatives to implement the same logic, SQL Server will know the cost of each alternative, then it can pickup a most efficient one to run. However, databases nowadays are usually complicated. Very frequently, implementing a logic for data accessing can have millions of alternatives. Getting cost for each and find the cheapest best one is just so time consuming. It doesn’t make sense to take a day to find a best plan to execute where the returning of the query can be done in 10 minutes by using the wrost plan. There are definitely some rules behind. We will come back to the rule in the future. Now let’s see how SQL Server gets estimated number of rows on the data it maniputes on.
Query Plan (07) – Nested Loop
Relationships amoung multiple sets can always be interpreted into multiple relationships of 2 sets – joins. Conceptually, you can have 2 types of joins, Inner Join and Outer Join. Inner joining returns the conjunction of two sets, such as Inner Join, Cross Apply, and Intersect in SQL Server. Outer join will return full set from one or both of the inputs with or without relations between each other such as Left Outer join, Right Outer Join, Full Outer Join, Cross Join, and Outer Apply. In SQL Server, if rows are only returned from one set not the other, it’s called Semi Join, such as Exists, IN (subset). If returning rows do not exist in another set, it’s called Anti Semi Join, such as NOT Exists, Except, Not In (subset). They are all conceptual. Nested loop is a PHYSICAL operator, it supports any of types of joins described above.
Query Plan (06) – Seek
Seek operator presents both physical and logical operator. It can only apply to an index, clustered index or none clustered index. It’s the most efficient operation to reach a record in an index by key. As we know, indexes are organized in a B-Tree, each record in the non-leaf level of B-Tree includes a the first key(s) in the page of next level and the pointer (File:Page:Slot) of the page in the next level.
Query Plan(05) – Scan
Few factors can cause SQL Server to scan a table.
- Hint has been used, such as undocumented table hint ForceScan, wrong index is specified for a table.
- No index can be utilized for seeking
- The query selects everthing, no where clause.
- Predicates are not selective.
Query Plan(04) – Basic Properties
Every operator has its own properties. Reading those properties can help understand the logics behind them. Let’s have a glance on a query plan of a simple query
create table #t(Value int) insert into #t (Value) values(1) select * from #t
Query Plan(03) – Operators
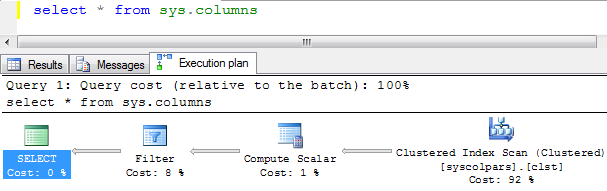 Query plan constists of set of steps as I mentioned previously. These steps also called operators. The data flows from right operators to left. Each operator can also be called node. The SELECT is not a node. The node number is from left to right, for instance, Filter is Node 0, Compute Scaler is Node 1, and Clustered Index Scan is Node 2. By looking at this plan, you might roughly tell what the query does behind – The data is acquired by scanning a clustered index on syscolpars table(Clustered Index Scan operator). Rows are sent to Compute Scalar operator for calculations. After the calculation rows are sent to filter operator, data cannot match the condition will be discarded and data satisfis the predicates will be output to client.
Query plan constists of set of steps as I mentioned previously. These steps also called operators. The data flows from right operators to left. Each operator can also be called node. The SELECT is not a node. The node number is from left to right, for instance, Filter is Node 0, Compute Scaler is Node 1, and Clustered Index Scan is Node 2. By looking at this plan, you might roughly tell what the query does behind – The data is acquired by scanning a clustered index on syscolpars table(Clustered Index Scan operator). Rows are sent to Compute Scalar operator for calculations. After the calculation rows are sent to filter operator, data cannot match the condition will be discarded and data satisfis the predicates will be output to client.