
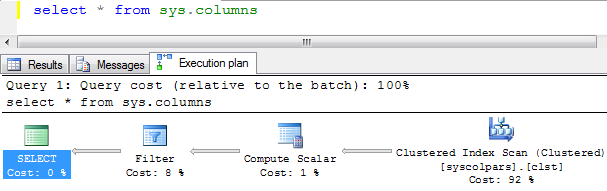
 Query plan constists of set of steps as I mentioned previously. These steps also called operators. The data flows from right operators to left. Each operator can also be called node. The SELECT is not a node. The node number is from left to right, for instance, Filter is Node 0, Compute Scaler is Node 1, and Clustered Index Scan is Node 2. By looking at this plan, you might roughly tell what the query does behind – The data is acquired by scanning a clustered index on syscolpars table(Clustered Index Scan operator). Rows are sent to Compute Scalar operator for calculations. After the calculation rows are sent to filter operator, data cannot match the condition will be discarded and data satisfis the predicates will be output to client.
Query plan constists of set of steps as I mentioned previously. These steps also called operators. The data flows from right operators to left. Each operator can also be called node. The SELECT is not a node. The node number is from left to right, for instance, Filter is Node 0, Compute Scaler is Node 1, and Clustered Index Scan is Node 2. By looking at this plan, you might roughly tell what the query does behind – The data is acquired by scanning a clustered index on syscolpars table(Clustered Index Scan operator). Rows are sent to Compute Scalar operator for calculations. After the calculation rows are sent to filter operator, data cannot match the condition will be discarded and data satisfis the predicates will be output to client.
Why is so completed just for a simple select? The fact behind that sys.columns is a system view which is defined as below.
CREATE VIEW sys.columns AS
SELECT id AS object_id,
name, colid AS column_id,
xtype AS system_type_id,
utype AS user_type_id,
length AS max_length,
prec AS precision, scale,
convert(sysname, CollationPropertyFromId(collationid, 'name')) AS collation_name,
sysconv(bit, 1 - (status & 1)) AS is_nullable, -- CPM_NOTNULL
sysconv(bit, status & 2) AS is_ansi_padded, -- CPM_NOTRIM
sysconv(bit, status & 8) AS is_rowguidcol, -- CPM_ROWGUIDCOL
sysconv(bit, status & 4) AS is_identity, -- CPM_IDENTCOL
sysconv(bit, status & 16) AS is_computed, -- CPM_COMPUTED
sysconv(bit, status & 32) AS is_filestream, -- CPM_FILESTREAM
sysconv(bit, status & 0x020000) AS is_replicated, -- CPM_REPLICAT
sysconv(bit, status & 0x040000) AS is_non_sql_subscribed, -- CPM_NONSQSSUB
sysconv(bit, status & 0x080000) AS is_merge_published, -- CPM_MERGEREPL
sysconv(bit, status & 0x100000) AS is_dts_replicated, -- CPM_REPLDTS
sysconv(bit, status & 2048) AS is_xml_document, -- CPM_XML_DOC
xmlns AS xml_collection_id,
dflt AS default_object_id,
chk AS rule_object_id,
sysconv(bit, status & 0x1000000) AS is_sparse, -- CPM_SPARSE
sysconv(bit, status & 0x2000000) AS is_column_set -- CPM_SPARSECOLUMNSET
FROM sys.syscolpars
WHERE number = 0 AND has_access('CO', id) = 1
The operators showing on the graphical query plan are all physical operators. Clustered Index Scan physical operator scans the table via clustered index. Once a record is read, in this case, it will check if the number column of the record is 0. You can click on the operator, then press F4 to show the properties of the operator. One of the properties is Predicate, [master].[sys].[syscolpars].[number]=(0). If the record read satisfy number=0, it will be sent to next physical operator Compute Scalar which will be calculate all function calls, like convert and sysconv, and logical operator, such as &, for SELECT field list. After calculation, the record with the calculated values will be sent to next operator called Filter. It calls has_access function with inputing value id and constant ‘CO’, and determine if returning value of the function is 1. If it’s not, the record will be discard, otherwise, the record will be returned to the client. Then performs the same process for the second record, then the third, forth… until all records are processed.
In this example, a functions called in WHERE clause with columns passed in as parameters might lead SQL Server generate a filter operator. This operator has to test all the inputs with the criteria to decide which one should be returned. When number of inputs is huge and output is low, for instance, there few hundred million rows on right size but only 2 rows in output. The filter operator just keeps testing rows and discarding unneeded rows. This means that most of the data being read joinning to this operatore is useless. Effeciency of the query will be low. This is why it’s not a good practice performing calculations on fields in WHERE clause.
What would you think about this plan? Is it good? If you are the SQL Server, what would you do? My answer is that I will put Compute Scalar operator after(before in the graph, but after in the data flow) Filter operator. Because Compute scalar may take more time (cost) on more rows If do it before the filter. I can’t find out why SQL Server doing that in such way. In regular cases, only calculated column will generate the plan that scalar operator run before the filter operator.
All queries are interpreted to series of physical operators that SQL Server can execute. Loogical operators describe relationships to help people understand the queries. From perspective of relatioinship of two sets, SQL Server has logical operator inner join, cross apply, left outer join, right outer join, full outer join, cross outer join, and outer apply. While 2 sets joining together, if returns from the relation are only from one set, the relationship is called Semi join. Exists, In (sub-query), and intersect are semi joins. If one set does not exist in another, the relationship is called Anti Semi join, such as Not Exists, Not In (sub-query), Except. At physical level, there are only 3 physical operators interpreting all logical operators. They are Nested Loop Join, Merge Join, and Hash Join. Sone logical operator has the same name with physical operator, like Table Scan, Clustered Index Scan, clustered Index Seek, etc.
Hi John,
The Compute Scalar in this plan *defines* a number of expressions but the engine evaluates them lazily. Most of the expressions are not evaluated at all in operator visible in show plan output; they are computed when a later operation needs the expression result. More details at
Paul
Hm the link went missing: http://bit.ly/ComputeScalar