
Merge is a physical operator joining 2 sets together into one. Similar to Nested Loop, it can implement all logical join operations, such as outer join and inner join. Different from Nested Loop, Merge needs 2 input sets which are sorted on the joining keys. For instance, there are 2 piles of papers. The first pile includes customers’ basic information. Each paper has and only has one customers information. The first pile is sorted by customers’ ID. The second pile includes customers’ purchase information. Every customer might have 0 to many purchase orders. The second pile is sorted by customer’s ID. While merging taking place, operator takes one page from the first pile, Customer1 for instance, to compare the page from the second pile. If matched, return the combined information, then take the next page from the second pile and compare again. Until no more pages on the second pile can mach the current page from the first pile, which also means no more pages for Customer1 in the second pile, then the operator takes the second page from the first pile, and repeat this operation again and again until all the pages in the first pile get processed. This is a very effecient operation.
use tempdb
go
set statistics xml off
go
if object_id('SetA') is not null
drop table SetA;
create table SetA(SetAID int, constraint PKA primary key(SetAID))
go
if object_id('SetB') is not null
drop table SetB;
create table SetB(SetBID int, SetAID int, constraint PKB primary key(SetBID))
create index IX_SetB on SetB(SetAID)
go
if object_id('SetC') is not null
drop table SetC;
create table SetC(SetAID int)
create clustered index IX_SetC on SetC(SetAID)
go
set nocount on
declare @i int, @j int
select @i = 0
while @i < 100
begin
insert into SetA values(@i)
insert into SetC values(@i)
select @j = 0
while @j< 10
begin
insert into SetB values(@i*100 + @j, @i)
select @j = @j + 1
end
select @i = @i + 1
end
--go
update statistics SetA
update statistics SetB
update statistics SetC
In previous script, 3 sets are created. SetA has 100 records with clustered primary key SetAID. SetB has 1000 records with SetAID indexed. SetC has exactly same number of records as SetA but it only has a none unique clustered index on SetAID. Now lets execute following queries with Displan Execution Plan enabled.
select * from SetA inner merge join SetB on SetA.SetAID = SetB.SetAID select * from SetA inner loop join SetB on SetA.SetAID = SetB.SetAID select * from SetC inner merge join SetB on SetC.SetAID = SetB.SetAID
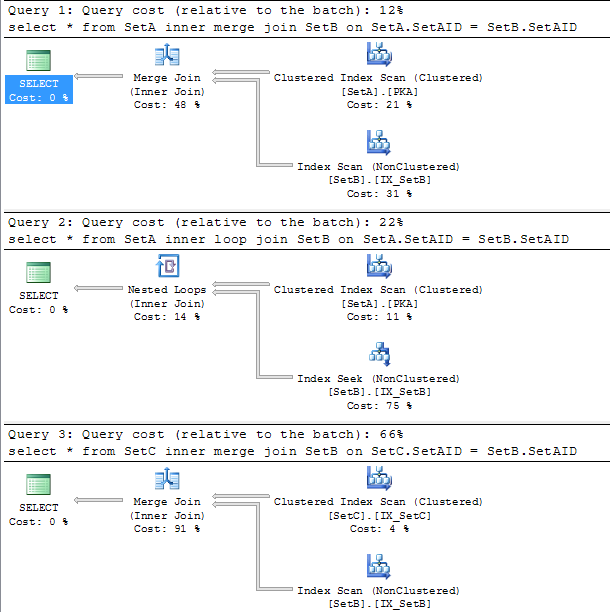
Those 3 queries return exactly the same. The first query uses merge key word to force optimizor to use merge join between 2 sets. It’s almost twice faster than the second query which uses Nested Loop. Look at the third query, it uses SetC to merge join SetB rather than SetA. The estimated cost of it is 3 times slower than the Nested Loop although SetC is same as SetA. Why is that?
After clicking on the merge operator in the execution plan of the third query, I figured that the property value of Many to Many is true.
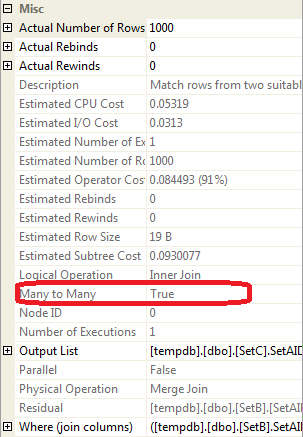
Since there is no unique constraints on SetC, SQL Server thinks the joining keys in SetC is not unique and whenever a duplicate happens in SetC, matched values from SetB needs to be returned again for the duplicte. This will require matched values from SetB to be buffered somewhere in SQL Server (memory or temp db) in case there is an duplicate from SetC needing those values. You can also see the Estimated IO Cost for this operator. This estimated cost happens to Many to Many merge but not One to Zero/One/Many scenario. Now, let’s run following queries
select * from SetC inner join SetB on SetC.SetAID = SetB.SetAID select * from SetC inner merge join SetB on SetC.SetAID = SetB.SetAID
The first query above does not have any joining hints. SQL Server uses Nested Loop. The second query use merge hint. The estimate of it is 3 times slower than the first one. Let’s turn on statistics time by “set statistics time on” and run those 2 queries few times, you will find that the second one is not always slow. So the estimate does not always reflect the reality.
Base on the table structures and data above, I come up with cost formula for one to many merge as below. This may not be accuate for all the cases.
CPU Cost (ms) = 5.613+(OuterRows-2)*(0.0065 + (InnerRowsPerOuterRow-2 )*0.0022) + (InnerRowsPerOuterRow-2)*(0.0044 + (OuterRows-2 )*0.0022) – (OuterRows-2)*(InnerRowsPerOuterRow-2)*0.0022
* OuterRows >=2, InnerRowsPerOuterRow >=2
If you have the same data distribution in the outer set (using SetC) without the unique constraint, the cost formular will be
CPU Cost (ms) = 5.79372+(OuterRows-2)*(0.09686 + (InnerRowsPerOuterRow-2 )*0.04738) + (InnerRowsPerOuterRow-2)*(0.04738 *2 + (OuterRows-2 )*0.04738) – (OuterRows-2)*(InnerRowsPerOuterRow-2)*0.04738
* OuterRows >=2, InnerRowsPerOuterRow >=2
The real formula for the the merge operator is more complex than what’s above.
Key for tuning a merge operator
- Use one to many rather than many to many. Unique index and constraints will help.
- Merge as little records as possible. Index over SARGs then Joining Keys might be useful.
- No large Joining keys and rows from the inner set. In M2M relationship, larger keys and rows will be buffered for reuse. If memory can’t fit the data, tempdb will be used.
John:
Thanks for presenting this in a very clear format.
I disagree with your first recommendation of using one to many relationship instead of a Many to Many. Performance should not define your schema, except in a reporting database. In that case, datamarts completely de-normalized make more sense than schema reduction.
If that was not what you intended in your recommendation I hope this stands as a clarification.
Cheers,
Ben
Thanks for visiting and leaving comments. Different opinions are always welcome. Merge itself is rather efficient. My first recommendation merely suggests making joining key from one of joining tables unique will help SQL Server make better decision on choosing physical algorithms and eventually help with the performance. M2M merge especially on merging huge sets might potentially take a lot of space on tempdb.