
Few factors can cause SQL Server to scan a table.
- Hint has been used, such as undocumented table hint ForceScan, wrong index is specified for a table.
- No index can be utilized for seeking
- The query selects everthing, no where clause.
- Predicates are not selective.
There are 2 kinds of scans, Index Scan and and Heap Scan, they scan all the records in a set. (Actually, there are more, such as log row scan, access transaction logs, which is not commonly used by developers. Constant scan which convert constants to a set and then pipe it to next operator. But those are not discussed in this post.) Index Scan scans an index through its B-Tree from beginning to end or the end to beginning logically depending on the order specified in the query. It can be clustered or none-clustered. Graphical Query Plan shows them in different icons but they are the same essentially. I just said the scan is “logically” since an index scan can’t always guarantee the output oder if there is no ORDER BY specified. While scanning, the operator can perform filters where you can detect them from Predicate property in the property list of this operator.
 Behind every operators, there’re formulars for cost estimate, so does index scan. After some research, I found that can be this:
Behind every operators, there’re formulars for cost estimate, so does index scan. After some research, I found that can be this:
CPU cost = 0.1581 ms + 0.0011 ms per extra row
IO cost = 3.125 ms + 0.7407 ms per extra page
If you have 2 rows in an index and both rows are in the same page, scanning them will take
CPU cost = 0.1582 + 0.0011 *1 = 0.1592 ms
IO cost = 3.125 + 0.7407 * 0 = 3.125 ms
Total cost = 0.1592 + 3.125= 3.2842 ms
Table scan can only happen to a heap. The operator first locates the extents from IAM, then goes to the data page and fetches rows back. Like index scan, it can have filters as well where it’s shown as Predicate property. This operator has its own cost formulars:
CPU cost = 0.0796 ms + 0.0011 ms per extra row
IO cost = 3.2035 + 0.7407 ms per extra page
If you have 2 rows in HEAP and both rows are in the same page, scanning them will take
CPU cost = 0.0796 + 0.0011 *1 = 0.0807ms
IO cost = 3.2035 + 0.7407 * 0 = 3.2035 ms
Total cost = 0.0807 + 3.2035 = 3.2842 ms
Obviously the starting CPU cost of HEAP scan is lower than starting Index Scan where starting IO cost of HEAP is higher than index scan. Put both IO and CPU cost together, the total estimated costs of both operator over same set of data are the same regardless how the data being organized.
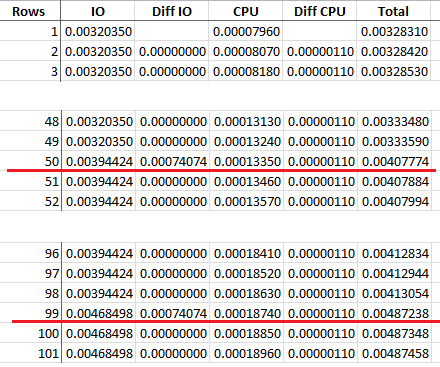
You might wonder how I know it. It’s simple. Run the query with one record in the table, you get the costs of the query, then insert one more record, free the cache, update the statisitcs, then run the query again, you will get the costs for 2 records. Repeat those steps for 3 records, 4, 5, …
I create a HEAP with the fact that the size of the record can make a data page to hold 49 records. I used the method explained above and then write down the cost for every run. Well you can see that the IO cost jumps every 49 records (a page) in which CPU cost crease linearly. This cost models above might be helpful for educational purpose. It might not be suitable for the table with large set since I haven’t done it yet. But consider this, the costs of data accessing above are so high. It easily triggers parallel processing threshold. I guess when the table getting bigger, the cost model will be different for those 2 operators, but the concepts should be the same. I will blog it once I have it pointed out. Please be aware of that those models are not officially published by Microsoft and I am sure Microsoft will/might have different definitions than I do
From there, we can see that keeping table or index narrow is the key of the performance. If you have table with large values, varchar(max), you set large value types out of row false, this will improve the performance only when you need to retrieve those large values in your query, but it will hurt the performce when they are not needed.