
In the real world, there are not only requirements on sequential or parallel process executions, but also requires complex ordering of the process executions. For instance, to complete a business process, you need to run Task 1 ~ 3 in parallel, wait until all tasks done, then perform task 4 ~ 6 at the same time. After those tasks are done, the entire process is done, or other processes may need to be lauched in the same way. In this case, how would you model it based on what we talked in last post in this series?
We can utilize the structure introduced in previously with little modifications.
create table Tasks
(
TaskID int identity(1,1) primary key,
ExecutionOrder int null,
TaskBody varchar(max) not null,
Status varchar(20) not null default('Pending') -- can be Pending, Running, and Finished
)
go
create index IX_ExecutionOrder on Tasks(ExecutionOrder)
create index IX_Status on Tasks(Status)
go
create table Logs
(
LogId bigint identity(1,1) primary key,
TaskID int not null,
ExecutionOrder int not null,
TaskBody varchar(max),
SPID int not null default(@@SPID),
StartTime datetime not null default(getdate()),
Endtime datetime
)
go
create procedure ExecuteTask(@TaskID int, @ExecutionOrder int, @TaskBody nvarchar(max))
as
begin
declare @LogID bigint
insert into Logs(TaskID, TaskBody, ExecutionOrder)
values(@TaskID, @TaskBody, @ExecutionOrder)
select @LogID = scope_identity()
begin try
exec(@TaskBody )
end try
begin catch
-- your error handling logics
end catch
update Logs set EndTime = getdate() where LogID = @LogID
end
go
create procedure TaskScheduler
(
@WaitingTime int = 30 -- when queue is empty, it waits for 30 second by default before quitting.
)
as
begin
declare @StartTime datetime, @TaskID int, @TaskBody nvarchar(max), @ExecutionOrder int
select @StartTime = getdate()
while(1=1)
begin
begin transaction
update top (1) t
set @TaskID = TaskID,
@TaskBody = TaskBody,
@ExecutionOrder = ExecutionOrder,
Status = 'Running'
from Tasks t with (readpast)
where t.Status = 'Pending'
and not exists(
select *
from Tasks t1 with(nolock)
where t1.ExecutionOrder < t.ExecutionOrder
)
if @@rowcount = 1
begin
exec ExecuteTask @TaskID, @ExecutionOrder, @TaskBody
delete from Tasks where TaskID = @TaskID
select @StartTime = getdate()
end
else
waitfor delay '00:00:00:100' -- wait for 100 milliseconds
commit -- we can commit anyways here
if datediff(second, @StartTime, getdate()) > @WaitingTime
break; -- if there is no task in the queue in last @WaitingTime seconds
end
end
go
create procedure ExecAsync (@SQL varchar(max), @ExecutionOrder int)
as
begin
insert into Tasks(TaskBody, ExecutionOrder) values(@SQL, @ExecutionOrder)
end
go
In line 4, I add ExecutionOrder column to Tasks table to indicate the location of the task in entire task series. Corresponding to the change of Tasks table, ExecutionOrder field is also added to Logs table, Line 16. From Line 57 ~ 61, the code in the queue reader, we check whether the tasks in previous orders are done. If yes, start the task, otherwise wait. A quick test of this piece of code is illustrated below.
Start 3 windows and run the queue reader on each of them
exec TaskScheduler
Start a new window and run (queue) the tasks
exec ExecAsync 'Waitfor delay ''00:00:10.100''', 100 exec ExecAsync 'Waitfor delay ''00:00:10.100''', 100 exec ExecAsync 'Waitfor delay ''00:00:10.200''', 200 exec ExecAsync 'Waitfor delay ''00:00:10.200''', 200 exec ExecAsync 'Waitfor delay ''00:00:10.200''', 200 exec ExecAsync 'Waitfor delay ''00:00:10.300''', 300 exec ExecAsync 'Waitfor delay ''00:00:10.400''', 400 exec ExecAsync 'Waitfor delay ''00:00:10.400''', 400 exec ExecAsync 'Waitfor delay ''00:00:10.500''', 500
Then query the Logs Table
select * from Logs with (nolock)
LogId TaskID ExecutionOrder TaskBody SPID StartTime Endtime ----- ----------- -------------- ---------------------------- ---- ----------------------- ----------------------- 1 1 100 Waitfor delay '00:00:10.100' 58 2012-01-09 13:20:01.997 2012-01-09 13:20:12.100 2 2 100 Waitfor delay '00:00:10.100' 57 2012-01-09 13:20:12.100 2012-01-09 13:20:22.200 3 5 200 Waitfor delay '00:00:10.200' 57 2012-01-09 13:20:22.200 2012-01-09 13:20:32.403 4 3 200 Waitfor delay '00:00:10.200' 53 2012-01-09 13:20:22.203 2012-01-09 13:20:32.403 5 4 200 Waitfor delay '00:00:10.200' 58 2012-01-09 13:20:22.203 2012-01-09 13:20:32.403 6 8 400 Waitfor delay '00:00:10.400' 53 2012-01-09 13:20:32.407 2012-01-09 13:20:42.807 7 6 300 Waitfor delay '00:00:10.300' 57 2012-01-09 13:20:32.407 2012-01-09 13:20:42.707 8 7 400 Waitfor delay '00:00:10.400' 58 2012-01-09 13:20:32.407 2012-01-09 13:20:42.807 9 9 500 Waitfor delay '00:00:10.500' 57 2012-01-09 13:20:42.810 2012-01-09 13:20:53.310 (9 row(s) affected)
You can see that any task with the same execution order are running at the same time. Especially entries LogID 6, 7, and 8, those 3 tasks started even at the exactly same time with precision down to millisecond.
Reality is alway complexier than the plans. In your system, you may have multiple processes with each of which needs run its own tasks in parallel in specific order. If that’s the requirement, you only need to add a parent table to Tasks table, maybe call it Processes, which records the ProcessID with status and use Tasks table to record the tasks for each Process. Then change your queue reader and Logs table accordingly. I don’t have an example code here since there are many options to schedule the tasks. For instance, you have 5 pending processes with 100 tasks in each of them with 10 jobs (workers) in total predefined. It’s very possible that one process consumes all workers and others are starving from getting workers. But this is the true the case the business required. In another case, you may want to use round-robin fasion to schedule the processes, or you may want to prioritize the processes.
Seems like we have a perfect solution here. You then create 50 jobs in SQL Server agent with 10 second interval. After few days, you check the plan cache of SQL Server, you may get the same result as what I got below
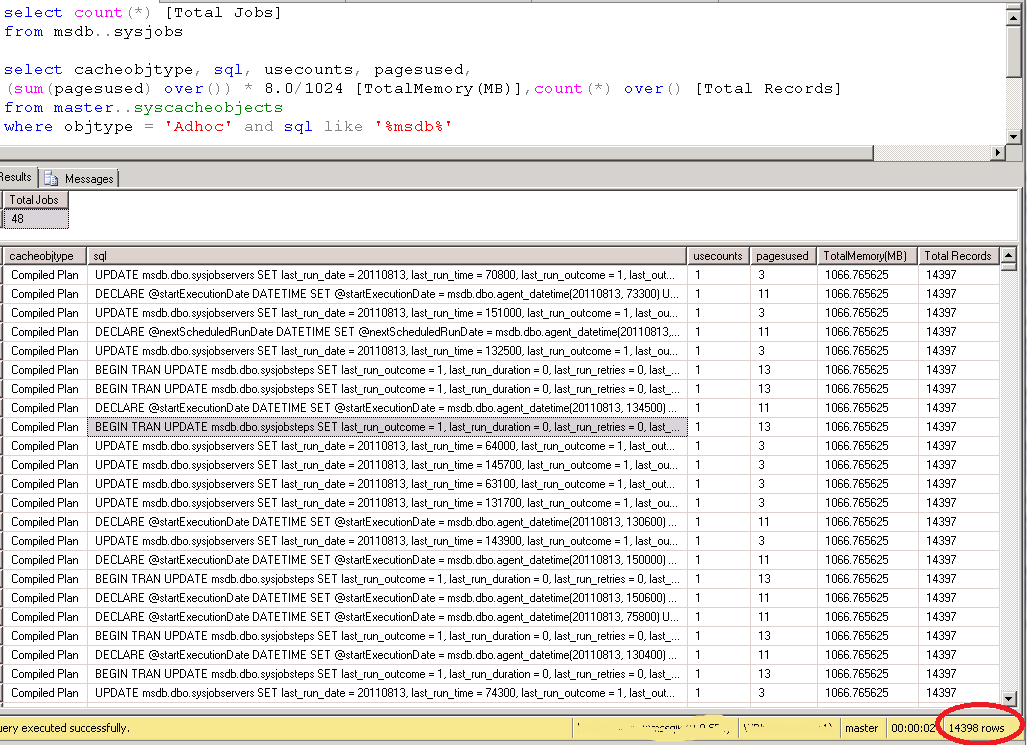
In this experiment, I created 48 jobs with interval 10 seconds. SQL Server (or agent) needs to use more than 1 GB of SQL Server memory to schedule them with 14K adhoc queries cached in the memory. You can see the overhead of using SQL Agents as a concurrent processing scheduler. In current SQL Server system, having 32 GB of RAM is a very common setup. Taking one Gig out is not a big deal, but use 1 GB memory for scheduling 50 workers is not a efficient way. In next post, I will introduce a lighter way to schedule tasks in SQL Server with pure T-SQL>