Last post, I talked about Customized Event and setting up trace for web applications which usually use pooled connection. Assuming you already have everything setup, SqlCommand component has been wrapped up to send an customized event with user or session information before an actually procedure call taking place. The trace is also setup to receive both procedure calls and customized events. To simplify the scenario, trace only capture the customized event and RPC Complete with column SPID, TextData, StartTime. To receive the trace data, you can either save them to the disk then read the trace file from the disk or directly stream the trace data.( see my post here for detail). After trace data being read, there will be always a customized event prior to an actual procedure call. When you are asked to get SQL Server response time for an particular application, for instance, give me average respose time of procedure ABC every 30 minutes during the day for that user, you can query the table includes the trace rows to locate all procedure ABC, then based on SPID and identity values to find previous record to get the user information of the procedure call, perform filter, aggregates…It will be fine if your table is small. The trace system generate more than 500MB data every hour, performing such query will be very challenging irrespective of how you design the indexes on the trace table. Now you may think to re-format the trace data to table with columns, EventID, SPID, TextData, StartTime, and UserInfo to simplify the query. But SQL Profiler cannot do it in that way, you will have to write an ETL for that.
Read more

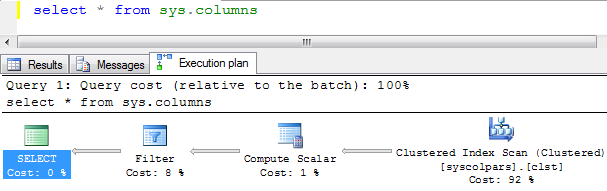 Query plan constists of set of steps as I mentioned previously. These steps also called operators. The data flows from right operators to left. Each operator can also be called node. The SELECT is not a node. The node number is from left to right, for instance, Filter is Node 0, Compute Scaler is Node 1, and Clustered Index Scan is Node 2. By looking at this plan, you might roughly tell what the query does behind – The data is acquired by scanning a clustered index on syscolpars table(Clustered Index Scan operator). Rows are sent to Compute Scalar operator for calculations. After the calculation rows are sent to filter operator, data cannot match the condition will be discarded and data satisfis the predicates will be output to client.
Query plan constists of set of steps as I mentioned previously. These steps also called operators. The data flows from right operators to left. Each operator can also be called node. The SELECT is not a node. The node number is from left to right, for instance, Filter is Node 0, Compute Scaler is Node 1, and Clustered Index Scan is Node 2. By looking at this plan, you might roughly tell what the query does behind – The data is acquired by scanning a clustered index on syscolpars table(Clustered Index Scan operator). Rows are sent to Compute Scalar operator for calculations. After the calculation rows are sent to filter operator, data cannot match the condition will be discarded and data satisfis the predicates will be output to client.