
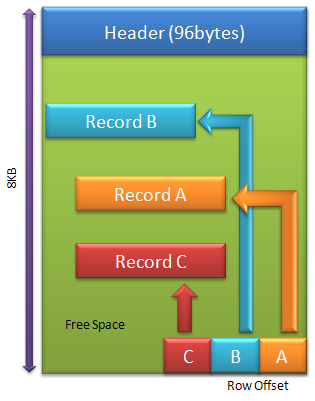
 There are different types of pages in SQL Server. No matter what types of pages are, the layout of the page is the same. A data file consists of numbers of 8k-pages. A Page includes 8192 bytes. First 96 bytes are used for header. The rest of the space is for data. A variable length row offset array (or slot array) is located at the end of every page and grows backwards. Count of records (size of array) is saved in the header. The size of each element in the offset array is 2 bytes. Records in a page are not sorted even though it is an index page. If the data needs to be sorted, the offset array will be is sorted by the key of the index.
There are different types of pages in SQL Server. No matter what types of pages are, the layout of the page is the same. A data file consists of numbers of 8k-pages. A Page includes 8192 bytes. First 96 bytes are used for header. The rest of the space is for data. A variable length row offset array (or slot array) is located at the end of every page and grows backwards. Count of records (size of array) is saved in the header. The size of each element in the offset array is 2 bytes. Records in a page are not sorted even though it is an index page. If the data needs to be sorted, the offset array will be is sorted by the key of the index.
As far as I know, there are about 14 types of pages in SQL Server data file.
- Type 1 – Data page.
- Data records in heap
- Clustered index leaf-level
- Location can be random
- Type 2 – Index page
- Non-clustered index
- Non-leave-level clustered index
- Location can be random